前回のおさらい - データベース正規化を自動化してみようと思った経緯
- 超高速開発ツールの普及が進んでおり、弊社でも「Web Performer」を導入
- 各社のツールを比較検討してみたけど、どれも現時点ではまだ、AIではない
- もっとAIチックな機能を持たせてみたら、ユーザーが喜ぶのでは?
- 例えば、「最適なデータベース設計の提案」はどうだろう?
- 正規化という王道の手法があるので、実験がしやすそう
- やってみよう
前回の記事でやったこと
第一正規形のデータベースを入力すると、すべての候補キーを検出するアルゴリズム(擬似コード)を記述。二分木を使った処理の内容を解説しました。
今回は、アルゴリズム(擬似コード)だけでなく、C++のソースコードも掲載しています。ぜひ、データベースの自動正規化を実行してみてください。
目的
第一正規形で与えられた任意の単一テーブルについて、ボイスコッド正規形への無損失分解を行うアルゴリズムを構築する。
目標としてはボイスコッド正規形までの分解でしたが、今回は尺の都合で、第二正規形(2NF)までの正規化を行うアルゴリズムを提案・実装しています。
2NF、3NF、BCNFはいずれも、関数従属性を取り扱うという点で共通しています。なので、2NFの自動化ができれば、3NFやBCNFへのステップアップにはさほどの困難はなさそうです。
今回も、用語については下記の書籍に則っています。
第一正規形(1st normal form, 1NF)とは?
正規化の対象であるRDBのRは「リレーショナル(Relational)」の頭文字ですが、これはリレーショナルモデルという数学的モデルに立脚しているということから付いた呼称です。同モデルの主要概念である「リレーション」の定義を満たすデータベースを第一正規形と呼び、具体的には、以下の条件を満たす必要があります。
- 繰り返しグループ(同一セルに2つの値を含むなど)が存在しない
- データにNULLは含まれない
今回は、入力されるテーブルが第一正規形であることを仮定して、議論を進めます。
第二正規形(2nd normal form, 2NF)を自動生成するアルゴリズム
第二正規化を自動化するにあたり、まずは第二正規形の定義を見てみましょう。
2NFの定義
1NFの条件を満たし、部分関数従属性を持たないテーブルは2NFである。
さて、この定義の中で「部分関数従属性」及び「関数従属性」についてご存知ない方は、以下の段落を読んでおいてください。
関数従属性(Functional depenency, FD)とは?
関数従属性とは、テーブルにおける、2つのカラム集合に関する概念です。
あるテーブルにおいて、$A$というカラム集合の値が同じなら、$B$というカラム集合の値も同じである時、$B$は$A$に関数従属していると言います。
この概念を説明する喩えとして、以下のテーブルを見てください。
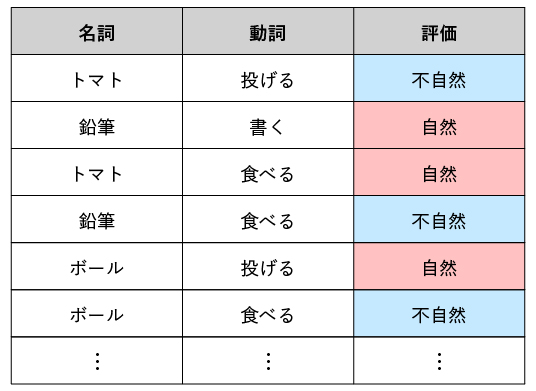
上図は、与えられた「名詞」と「動詞」の組み合わせが「自然であるかどうか」を表すテーブルです。
この時、「鉛筆」という名詞だけに対して「自然」か「不自然」かの判定はできません。 「食べる」という動詞に対しても同様です。 しかし、「鉛筆」「食べる」という組み合わせに対しては、それが「不自然」であるという判定を下すことができます。
このことから、${\mbox{評価}}$というカラム集合は、${\mbox{名詞}}$や${\mbox{動詞}}$といったカラム集合には関数従属しておらず、${\mbox{名詞}, \mbox{動詞}}$というカラム集合には関数従属していることが分かります。 なお、上記のテーブルには、他のいかなる関数従属関係もありません。
ここでは分かりやすさのために、カラム同士の関係性が明確な例をあえて選びました。 勿論一般に、関数従属関係はカラムの名称ではなく、テーブルの内容によって決まります。 例えば、以下のテーブルを見てみましょう。
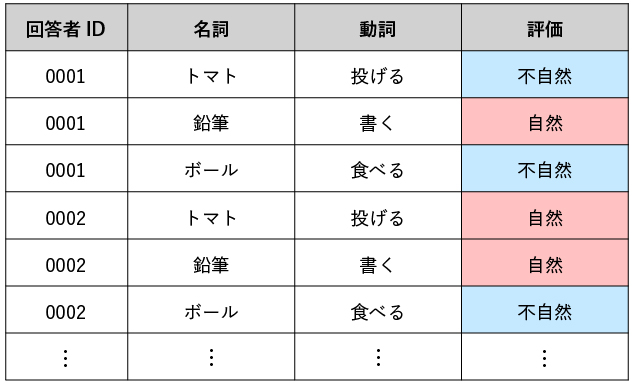
上図は、はじめの図とよく似ていますが、「名詞と動詞の組み合わせが自然だと思うか?」というアンケートの結果をイメージした表に変わっています。 着目すべきは、「トマト」「投げる」という組み合わせについて、ある人は「自然」、またある人は「不自然」と答えていることです。テーブルがこのような状態になっていると、「トマト」「投げる」という組み合わせが自然か不自然か、データからは一意に定まりません。ゆえにこのテーブルでは、${評価}$は${\mbox{名詞}, \mbox{動詞}}$に関数従属していないことになります。
このように、関数従属関係は、テーブル内のデータによって定まることに注意してください。
また、説明する相手がエンジニアであれば、以下の説明は分かりやすいかもしれません。
- カラム集合$A$の値をkey、$B$の値をvalueとして、両者の関係を一つの連想配列に格納可能であるとき、$B$は$A$に関数従属しているという
上記の定義は、これから行う関数従属性の判定において活用することになります。
部分関数従属性(Partial functional dependency)とは?
部分関数従属性は、ある条件を満たす関数従属性のことです。 定義の紹介の前に、まず候補キーについて復習しておきましょう。
復習:候補キーとは?
以下の条件を満たすカラム集合を「候補キー」と呼びます。
- テーブル内のデータを一意に定めることができる
- カラムを一つ除くと、データを一意に定めることができなくなる(既約性)
例えば上図においては、${\mbox{回答者ID}, \mbox{名詞}, \mbox{動詞}}$が唯一の候補キーです。
また、ある集合に対し、要素を一つ以上取り除いた別の集合を真部分集合と呼びます。たとえば、${\mbox{回答者ID}, \mbox{名詞}, \mbox{動詞}}$に対して${\mbox{名詞}, \mbox{動詞}}$は真部分集合です。
以上の用語を用いると、部分関数従属性とは、ある候補キーの真部分集合から、その候補キーに含まれないカラム集合への関数従属性であると定義できます。
そして、第二正規形は、第一正規形であり、部分関数従属性を含まないデータベースとして定義されます。
実は、上図のテーブルは部分関数従属性を持たないため、第二正規形になっています(もっと言うと、さらに高次の正規形であるボイスコッド正規形になっています)。よって、この条件を満たさないような別の例を考えてみましょう。
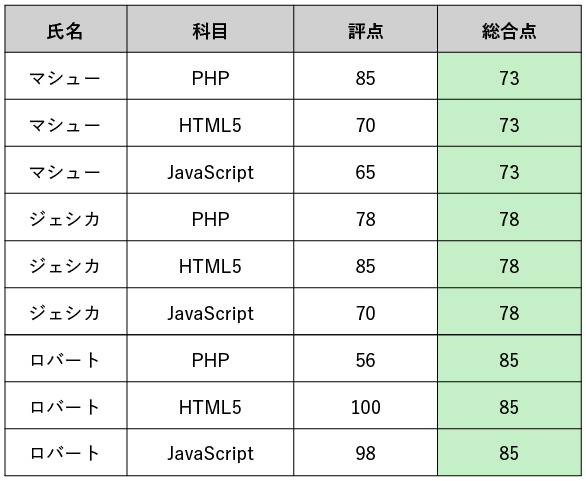
上表は、3人の生徒に対し、3つの科目の試験を行った結果をイメージしたテーブルです。 各生徒について、各科目の評点の平均値を丸めたものを総合点としています。 テーブルより、${評点}$は${氏名, 科目}$に関数従属しており、${\mbox{総合点}}$は${\mbox{氏名}}$に関数従属していることが分かります。 このテーブルには、部分関数従属性が存在するでしょうか?
まず、候補キーは${氏名, 科目}$であることが分かります。候補キーの真部分集合は${\mbox{氏名}}$もしくは${\mbox{科目}}$の2通りですが、${\mbox{氏名}}$から${\mbox{総合点}}$への関数従属性が存在しており、これが部分関数従属性であることが分かります。
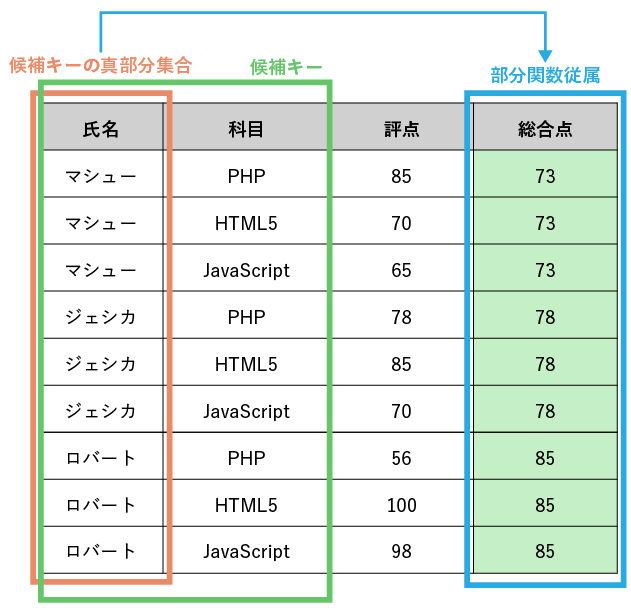
このような、部分関数従属性を持つ(第二正規化されていない)テーブルの弱点の一つとして、「更新による異常が起きやすい」という性質があります。例えば、上記のテーブルに対し、第4の科目である「Ruby on Rails」の評点を加えたとしましょう。 その際、全科目の平均値である総合点を更新する必要に迫られますが、以下のようなテーブルへと更新してしまう恐れがあります。
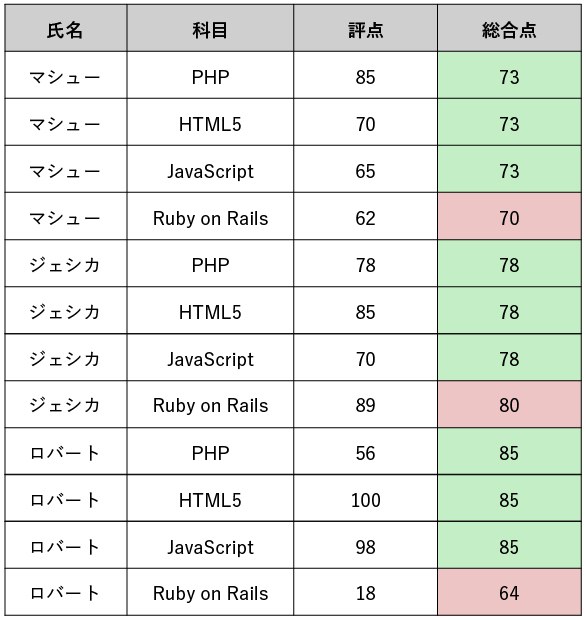
- 各生徒に関する「Ruby on Rails」の評点を追加
- 総合点の数値を再計算し、追加行に格納
- しかし、元々テーブル内にあった「PHP」「HTML5」「JavaScript」行の総合点を更新し忘れてしまった
テーブルがこのような状態になっていると、${氏名}$に対して${総合点}$が一意に定まらず、複数ある値のどれが正しい値かわからない状態になります。テーブルの性質上${\mbox{総合点}}$は${\mbox{氏名}}$に関数従属すべきなのに、そうなっていない状態は一種の矛盾です。第二正規形でないテーブルは、更新による矛盾が起きやすいテーブルと言えます。
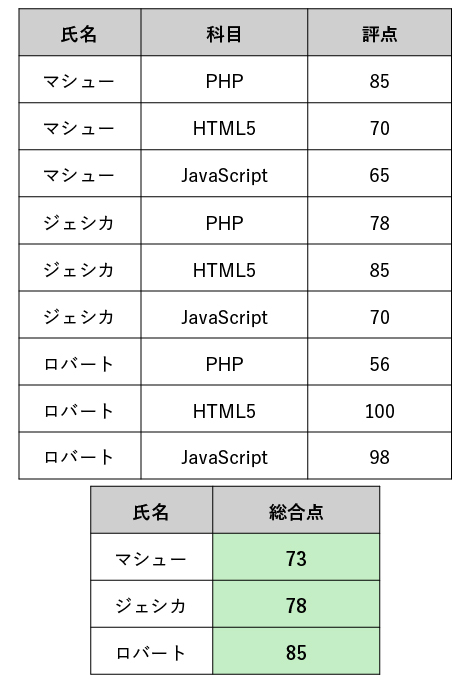
このテーブルから部分関数従属性を取り除くには、テーブルの分解が必要です。分解には射影(MySQLで言うところの、DISTINCT指定したSELECTコマンド)を用います。
今回の場合、以下の2つのテーブルに分解すれば、情報を損失させずに分解が可能です(無損失分解)。
第二正規化を自動で行うには?
第二正規化の自動化は、大きく3つのステップからなります。
- 候補キーを検出する
- 部分関数従属性を検出する
- 射影によって部分関数従属性を取り除く
このうち、1.については前回の記事でアルゴリズムを設計しましたので、今回は候補キーの一覧が手に入ることを前提に話を進めます。
部分関数従属性の検出
アルゴリズムを記述するために、幾つかの記法を決めておきましょう。 まず、カラム集合$A$からカラム集合$B$への部分関数従属性が存在することを、$A \rightarrow B$と表記します。先の例で言えば、${氏名} \rightarrow {総合点}$が成り立っていました。 また、検出される全ての関数従属性を$\mbox{PFD}$で表します(Partial Functional Dependencyの略)。 実装上は、$\mbox{PFD}$は連想配列を使うと良いでしょう。
テーブルの全ての候補キーの集合を$\mathcal{K}$(花文字の$K$)で表すこととし、個々の候補キーを$K (\in \mathcal{K})$で表します。 また、集合の記法にしたがって、カラム集合$A$が候補キー$K$の真部分集合であることを、$A \subsetneq K$と表すことにします。 テーブルに含まれる全てのカラムからなる集合を$C$とすると、$K$に対する非候補キーの集合は、差集合$C\setminus K$で表されます。(差集合$C\setminus K$は、集合$C$の要素のうち、$K$に含まれない要素からなる集合のことです。)
アルゴリズムのアイデアは、候補キーの集合$\mathcal{K}$から任意の候補キー$K$を取って、その真部分集合$A \subsetneq K$が非キー属性${c}\:(c \in C \setminus K)$に対する関数従属性$A \rightarrow {c}$を持つかどうか、しらみ潰しに調べるというものです。 まだ調べていない候補キーの集合を$\widehat{\mathcal{K}}$で表すこととし(アルゴリズム開始時は$\widehat{\mathcal{K}} = \mathcal{K}$)、調べ終わった候補キーは$\widehat{\mathcal{K}}$から取り除きます。 そして、$\widehat{\mathcal{K}} = \emptyset$(空集合)となった時にアルゴリズムが停止するようにします。
前回と同様、レコード数(テーブルの行数)を$m$で表すこととし、テーブル全体を$R$、個々のレコードを$r_1, r_2, \dots, r_m \in R$で表します。
以上の記法を用いて、すべての部分関数従属性を検出するアルゴリズムを記述してみましょう。

上記の擬似コードはアルゴリズム分野の書き方に倣い、代入を$=$ではなく$:=$、等値演算子を$==$ではなく$=$で書いていますので、ご注意ください。
下記は、擬似コードにコメントをつけたものです。

実装に関するコメント
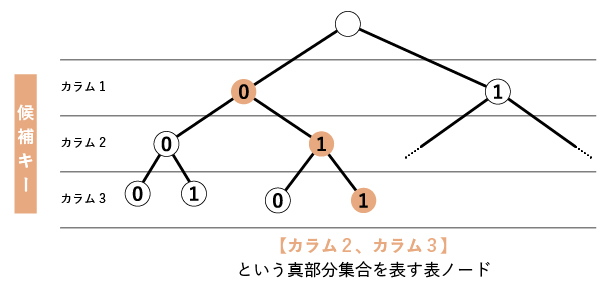
候補キー$K(\in \mathcal{K})$について、その全ての真部分集合を列挙する際には、前回も活用した二分木を使うのが筋の良い方法です。
第二正規化の方法
部分関数従属性の検出ができれば、第二正規化を自動的に行うのはさほど難しくありません。部分関数従属性にしたがってテーブルを分解していくことで、第二正規化を行うことができます。
ただし、候補キーが複数あるような場合は処理が複雑になりますので、ある候補キー$K$について部分関数従属性が検出された場合、一旦それを取り除いておいてから、分解後のテーブルに対してもう一度部分関数従属性の検出を行うといった段階的な実装をしたほうが、バグは少なくなりそうです。 また、分解の順序によって、結果として得られるテーブルの構成がどのように変わるかという点について、議論の余地があります。
第二正規化を自動で行うC++プログラム
ディレクトリ構造は以下のようになっています。
.
├── makeDB_test.cpp
├── table.hpp
├── makeDependentData.hpp
├── dependency.hpp
└── hashVI.hpp
各ファイルの機能は以下の通りです。
| ファイル | 説明 |
|---|---|
| makeDB_test.cpp | 正規化を行う対象のテーブルがもつ関数従属性を指定して生成、第二正規化を実行 |
| table.hpp | RDBMSのテーブル操作(SELECT, SELECT DISTINCT, etc.)や、候補キー検出・関数従属性検出・第二正規化アルゴリズムを実装。本プログラムの心臓部 |
| makeDependentData.hpp | 指定された関数従属性をもつテーブル生成機能を実装 |
| dependency.hpp | 関数従属性のプログラム上での表現(dependency構造体)を定義 |
| hashVI.hpp | vector<int>型からハッシュ値を発行する関数オブジェクトを定義 |
プログラムに関する補足
各テーブルを二次元vector(vector< vector <int> >型オブジェクト)で擬似的に表現し、RDBMSのSELECT DISTINCTコマンドはハッシュを使って自力で実装しています。 対象テーブルの行数を$m$, カラム数を$n$としたとき、SELECTコマンド、SELECT DISTINCTコマンドの計算量は以下の通りです。
| コマンド | 計算量 |
|---|---|
| SELECT | $\mathcal{O}(mn)$ |
| SELECT DISTINCT | $\mathcal{O}(mn)$ |
ハッシュを使うなどデータ構造の工夫をしないと、両者の計算量は一致しません(DISTINCT指定すると遅くなってしまう)。 具体的な要件としては、vectorをkeyとして用いることのできるハッシュ(連想配列)が必要になります。今回はデータ型がintのみだったので簡単でしたが、任意の型の組み合わせだとややこしいことになりそうです。
第三正規化とボイスコッド正規化
さらに高度の正規化である第三正規化、ボイスコッド正規化についても、第二正規化と類似した手続きで行うことができます。
- 取り除くべき関数従属系を検出
- 検出された関数従属性に従い、テーブルを分解
その具体的な方法についても、本記事に反響があれば追記していきたいと思います。
関連記事
- 2017/04/28 超高速開発とAIに関する一考察 DBにおける候補キーの自動検出アルゴリズムを書いてみた 正規化という概念を知らないようなユーザーでも、サンプルとなるテーブルを与えれば、正規化されたテーブルが出力されるようなアルゴリズムを考えてみました。
- 2024/01/25 TypeScriptで名前付き引数っぽい実装をする TypeScriptでPythonのように関数呼び出し時に引数名を使って「名前=値」の形式で引数を指定するOptions Objectパターンという技を紹介します。
- 2023/10/17 コードの品質を測定する方法 コードの品質を測定する方法が紹介されていました。計測の自動化に向けて、少しまとめてみました。
- 2023/01/26 デメテルの法則 「直接の友達とだけ話すこと」というプログラミングのお約束です
- 2020/06/15 PySparkの分散される処理単位であるクロージャと共有変数の仕組み Spark では、処理が分散されて、複数のノードやスレッドで実行されますが、分散される処理の塊を、どう配信しているのか?加えて、複数のタスク間でのデータの共有とか、集約するための仕組みがどうなっているのか?少しだけ説明します。