可読性が高く、高速な「連想配列」
エンジニアであれば、「連想配列」のお世話になる機会は多いと思います。言語によりますが、任意のデータをkeyとして指定できる連想配列は、 コードの可読性を高く保ったまま、ニーズに合わせた柔軟なシステム実装をサポートしてくれる強力なツールです。
ユーザーとして連想配列を使う分には、普段あまり意識しませんが、 各言語に標準実装されている連想配列の利便性は、下記の2点を満たすことで支えられています。
- keyを引数とすることでvalueを取り出す(もしくは代入する)操作が簡便であること
- 上記の操作が、連想配列に格納済みのデータサイズによらず高速であること(重要!)
今回は、普段お世話になっている「連想配列」について、あらためてその成り立ちや性質を見直してみたいと思います。 本記事(および 次回)は、
- 「連想配列はどんな技術で実現されている?」疑問に思った方
- 「自分で連想配列を実装してみたい」という物好きな方
- 「平均検索速度が定数時間O(1)ってどういう意味なんだ」と疑問に思い夜も眠れない方
に捧げます。
連想配列は、配列ではない!
(みなさんの興味を惹くために、ちょっとラジカルな見出しをつけてみました。)
本記事では、配列と連想配列を 似たようなものとみなすことをやめ、その成り立ちを解剖する ことで、 連想配列(特にハッシュによるもの = ハッシュテーブル)がいかにありがたいツールであるかを明らかにしてみたいと思います。 なお、ここまでで御察しの通り、 筆者は連想配列、ハッシュテーブルが大好き です。 まだエンジニアリング経験の浅い学生時代、C++を中心にコーディングをしていたのですが、 C++11に unordered_map クラスとして連想配列が存在することを知らず、自前のハッシュテーブルを作ったりしていました。 要素へのアクセスが目に見えて高速化され、とても感動した覚えがあります。
連想配列と配列の対比
さて、連想配列と配列の違いについて詳しく見ていきましょう。 両者の共通点といえば、
- データを格納するために、メモリを使うこと(あたりまえ)
- key(もしくは添字)の指定によってデータにアクセスすること
であり、逆にいえば それくらいしか共通点はない 、と筆者は認識しております。 そのわずかな接点についても、下記のような違いがあり、むしろこの相違点が「配列と連想配列の違いである」と理解されている方も多いかと思います。
| point | 配列 | 連想配列 |
|---|---|---|
| 確保するメモリ領域の広さ | 任意、もしくは言語ごとの実装により動的確保 | 言語ごとの実装による |
| 指定するkey(添字) | 確保するメモリ領域の先頭からのオフセット(ゆえに整数に限る) | 任意(整数や文字列など) |
ですが、実は上記のちがい以上に、 key(添字)・valueの組による値の参照/代入の過程 が、大きく異なっている点が両者の違いの本質です。 以下では、簡単な実験的実装をテーマに、両者のロジックの中身がどう異なるかを明るみにしてみたいと思います。
Rubyの配列を(無理やり)連想配列にしてみよう
なお、Rubyの連想配列クラスはHashクラスですが、これはハッシュ関数を用いて実装されたハッシュテーブルであることを意味します。 今回は、連想配列の定義を、
- keyに対するvalueを記憶させることができる (
array["altus"] = 5) - keyを渡すと、記憶されているvalueを取得できる (
p(array["altus"]) #=> 5) - keyに対するvalueを上書きすることが出来る (
array["altus"] = 50 #"altus"に対応するvalueを50に上書き)
であるとし、Hashクラスとは別の 「粗悪な」 連想配列を作ってみたいと思います。
「粗悪な」連想配列を実装してみる
まずは、下記ソースコードをご覧ください。
上記コードは、RubyのArrayクラス(配列クラス)を継承し、MyAssociativeArrayクラスを生成しています。 要素取り出し []と代入演算子[]=をオーバーロードすることで、 arr["altus"] = 5 や p(arr["altus"]) といったアクセスが実現。 MyAssociativeArrayクラスを 連想配列として用いる ことに成功していることがわかりますね。
ほか、値の上書きや、存在しないkeyに対してnilを返すといった実装にも成功しており、 Arrayクラスをベースに、とりあえず連想配列として使える実装ができたことがわかります。
どうやっているのか、以下ソースコードの解説をしていきます。
RubyのArrayクラスを継承・メソッドをオーバーロードして連想配列にするまで
代入メソッド([]=)の実装
まず、Arrayクラスを継承し、MyAssociativeArrayクラスを定義します。
そのため、MyAssociativeArrayクラスは、Arrayクラスの性質を受け継いでいます。 Rubyでは組み込みクラスのメソッドを上書きできるので(シンタックスシュガーの一種)、 「手軽かつ、パッと見わかりやすく、性能が悪いので反面教師にもなる」オリジナル連想配列が作れるのではないか、 というのが本記事のモチベーションでした(余談)。
さて、肝心のメソッド上書きの内容です。 はじめに「値の代入」に取り掛かりました。そのためにオーバーロードする必要のあるクラスメソッドは []=です。 このメソッドは第一引数に添字(key)、第二引数に値(value)を取ります。
今回の実装は、配列の要素としてkey, valueの組(2つの要素からなる配列)をもたせてしまおう という原始的なもので、 第一要素を 線形走査 することで、お目当ての要素にアクセスしたり、値を上書きすることができます(この点が 粗悪 たる所以です。詳しくは後述)。
代入すべきkey, valueが与えられた場合、まずは過去に格納したデータの中に、同一keyの値が存在しないかどうかを調べます。
もし存在すれば、該当する要素のvalueを上書きし(上記L9)、 存在しなければ、key, valueの組を新しく配列に格納します(下記コード)。
蛇足
第一要素がkey, 第二要素がvalueとみなす実装は、暗黙的な悪い実装なので、 連想配列の中身を連想配列で定義したくなりますが、もちろん今回は Hashクラスの利用は禁じ手です。
さて、これで値の代入ができるようになりました。
参照メソッドの実装
次は値の参照です。こちらも線形走査をする点は変わらないので、一気に紹介してしまいます。
たとえば p(arr["altus"])とすれば、arr において "altus" keyに対応する要素を返すので、 格納されているvalue、例えば 5が出力されるといった具合です。 もし該当するkeyの要素が存在しない場合は nilを返します。
代入・参照に線形時間かかる連想配列 - 上記実装は何が悪いのか?
さて、ここまで度々(しつこく?)触れてきた、上記連想配列の「粗悪さ」について解説してみたいと思います。
ここまでの実装をイメージ化すると、下図のようになります。
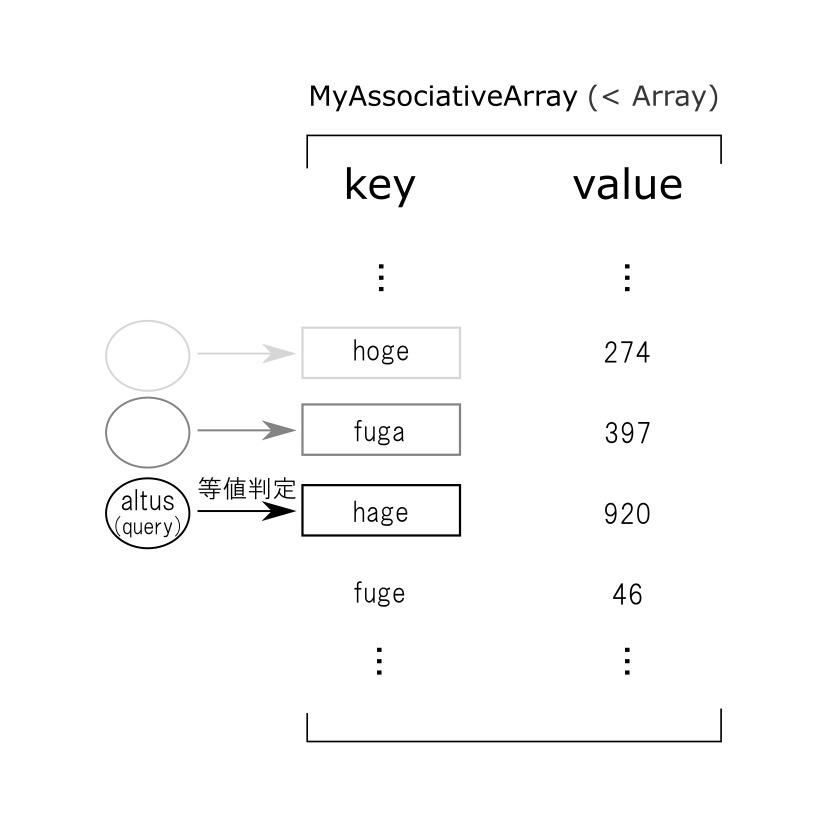
(代入・参照とも仕組みは同じなので、一つの図で済ませてしまいました。)
たとえばarr["altus"]のように、keyに対応するvalueを参照する処理や、 arr["altus"] = 5のような代入処理の際に、上図で表されるような処理、 すなわち「既存のkey一つひとつに対する、与えられたkey(query)との等値判定」を行って、 等値なものが見つかったタイミングでvalueを返したり、代入したりといった処理を行います。
これがいわゆる 線形走査 であり、において、データサイズnに対して比例する時間、すなわちO(n)の時間がかかります(最悪値評価)。
ちなみに、参照・代入における最悪ケースは何かと言うと、「まだ連想配列内に存在しないkeyをqueryとして投げた場合」 です。 非常によくあるケースが最悪値なので、この性能の悪さは実用上の障害になり、 ある程度データサイズが大きくなると、上記の連想配列はほとんど役に立ちません。
では、どうすれば性能の良い連想配列を得られるのでしょう… という問いへの答え(の一つ)が、 次回の記事でご紹介する「ハッシュテーブル」です。 ご期待ください!
参考資料
関連記事
- 2018/05/07 「ハッシュ」完全理解のための覚書 ハッシュテーブルをRubyで実装してみる 「ハッシュ関数」「ハッシュ値」「ハッシュテーブル」についてごまかしなく理解することを目的に、Rubyでハッシュテーブルクラスを自作してみました。ソースコードは100行に満たないので、コードリーディングを通じたデータ構造の理解にお役立てください。
- 2018/07/18 全文検索を自社サイト・社内サーバーに構築したいクライアントのための留意点 システム開発における「全文検索」の実装方式・コスト・性能に関して、クライアント企業の方にも腹落ち頂けるようまとめました。grep型と索引型の違いに関する平易な解説を記載しているので、これらをクライアントに解説されたい開発者にもオススメです。
- 2024/01/25 TypeScriptで名前付き引数っぽい実装をする TypeScriptでPythonのように関数呼び出し時に引数名を使って「名前=値」の形式で引数を指定するOptions Objectパターンという技を紹介します。
- 2023/10/17 コードの品質を測定する方法 コードの品質を測定する方法が紹介されていました。計測の自動化に向けて、少しまとめてみました。
- 2023/01/26 デメテルの法則 「直接の友達とだけ話すこと」というプログラミングのお約束です