弊社の機械学習への取り組み - VOCシステムの構築において
VOCとはVoice Of Customersの略称で、日本語訳は「お客様の声」というありふれたものです。
VOCは一種のビッグデータであり、自然言語処理にかけることで定量化が可能です。
弊社では、Pythonの自然言語処理プラットフォームであるNatural Language Toolkit(NLTK)や、独自手法による自然言語処理を組み込み、以下を実現するシステムを開発しました。
- 自動的に製品と風評情報を紐付ける
- レビュー内容の自動分類
また、自然言語処理については、WebサイトのRSSフィードから記事カテゴリを判別するという用途も有名です。RSSフィードには記事の要約が含まれています。この要約文章を定量化することで、機械学習手法による自動分類が可能になります。
このように、機械学習によって取り組むことのできる領域は大きくなっており、ライブラリの充実によって、用途次第では現実的なコストで開発ができるようになりました。
過去の記事でも述べた通り、弊社のスタッフは自然言語処理ライブラリの内部処理を決めるアルゴリズムや、そのバックボーンにある数学モデルの理解は雑学程度です。あくまでユーザとしてこれらのツールを選別し、使いこなすための努力を都度行います。
とはいえ、機械学習界隈の動向はある程度注視しています。機能を実現できる技術の存在を知らなければ選択肢にも上りませんし、ライブラリの中身(ソースコード)を見て挙動を読み解く際、機械学習理論に関する知識があれば有利です。
そんな折、「オンライン学習」という機械学習の分野があることを知りました。
バッチ学習とオンライン学習
「オンライン」という言葉からは、「コンピュータがネットワークと接続されている状態」が自然と連想されます。しかし、この文脈での「オンライン」はそういう意味ではないようです。 ここでの「オンライン」は、「バッチ(batch)」の対義語として用いられています。「バッチ処理」といった文脈でよく接する、あのバッチです。
「オンライン学習」と「バッチ学習」を隔てるのは、データに関する制約の有無です。バッチ学習の枠組みは、学習に必要なデータは、学習開始時から終了時まですべて手元に揃っていることを前提にしています。その前提の下で精度を高めたり、適切なパラメータに高速に収束させるためのモデル改良を行います。
一方、オンライン学習の場合、データは学習の最中にも到着します。また、全てのデータを学習終了時まで手元に置いておくことが要求されず、学習に使ったデータをすぐに捨てることもできます。
この性質が実務的なメリットをもたらすのは、例えば以下のような場合です。
- 非常に大きなデータから学習する必要があり、データ全体はメモリに入りきらない場合
- 最新情報の逐次入力によって精度を上げることが要求される場合(ex. 天気予報システム、渋滞予測システム)
- 個人情報に基づく学習を行っており、データを手元に保管することにリスクがある場合(ex. メールのスパム・非スパム分類)
言い換えれば、「データの到着が逐次的(sequential)であること」が解析に含まれているような機械学習手法を、オンライン学習と呼ぶようです。
いくつか、主要な概念やアルゴリズムについてまとめていきます。
Follow-the-Leader(FTL)アルゴリズム
オンライン学習においてもっとも単純なアルゴリズムとして知られるのがFollow the Leader(FTL)です。FTLは、現段階よりも早く到達したデータ(過去の全データ)を最もよく説明するようにパラメータを決める手法です。これを端的に「Follow the Leader」(先んじる者に従う)という言葉で表している訳ですね。
FTLはオンライン学習を実現する素朴なアルゴリズムとして知られており、実際には過学習を防ぐための正則化項を加えた改良版であるFollow-the-Regularized-Leader(FoReL)がよく使われているようです。
後悔最小化(Regrets minimization) / リグレット解析(Regrets analysis)
オンライン学習手法の構築や、その解析においては、「後悔(Regret)」という概念が用いられるようです。
自動運転車を例に、リグレット解析の概念的説明を試みる
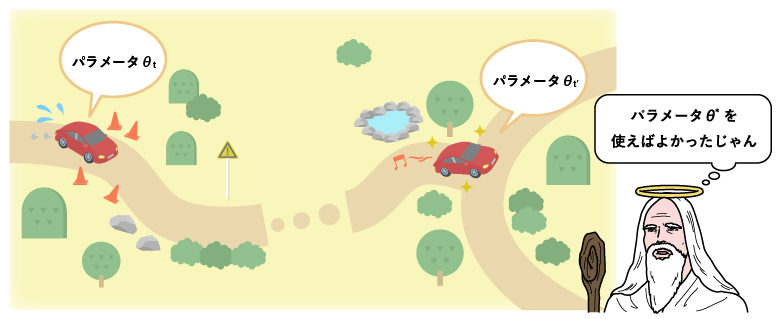
上記の挿絵においては、自動運転車の学習プロセスをイメージして、リグレット解析の概念を紹介しています。
(残念なことに、Googleなど多くの企業が2017年初頭に完全自動運転車の開発を断念してしまいましたが、あくまでここではイメージとして用いていますので、悪しからず。)
ここで、車は$ \theta $というパラメータ(ベクトル)に基づいて動作しています。オンライン学習においてはデータが到着する度にパラメータを更新していきますが、この例では、自動車が運転の最中に学習を行っていることでオンライン性を表現しています。
運転データを用いた訓練によって、自動車は学習を行い、パラメータを調整していきます。その過程において生じた「望ましくない出来事」を損失関数(loss function)を用いて定義し、それらの集計値(たとえば総和)の最小化を目指します。
それに対し、$ \theta^* $という最適パラメータがあり、それを用いて最初から最後まで車に運転させた場合を考えましょう。このようなパラメータは通常「神のみぞ知る」値であり、学習開始時点では(あるいは学習終了時点であっても)手にすることは出来ないことに注意しましょう。
通常は、$ \theta^* $の上で得られる損失は、学習過程の損失よりも小さなものになります。両者の差がどの程度小さいかによって学習アルゴリズムの良し悪しを図るのが、リグレット解析のアイデアです。
ここで、$ \theta^ $の下で得られる損失を$ L^ $、学習過程において得られた損失の差を$ L $とするとき、$ L - L^* $の値を後悔と呼びます。
この値は通常、プラスとなります。後悔の値をなるべく小さくなるようモデリングするのが「後悔最小化」というフレームワークです。
後悔の値は、優れたモデルを使うほどに小さくなります。反対に、最初から最適パラメータ$ \theta^* $を用いることが出来ていたら…という後悔は、学習過程における損失が大きいほど強まります。
予測におけるリグレット解析
オンライン学習ではデータの到着に従い、学習によって少しずつパラメータを調節していきます。なので、最初のうちはあまり精度が良くないとか、一時的に生じたトレンドにパラメータが引っ張られて全体傾向を捉え損ねるといったことが起こります。
一方、データが全て明らかになっている学習終了時点を考え、そこからデータを説明する「最適パラメータ」を引き出せば、都度パラメータを調整するオンライン学習の結果より良い結果になると言えそうです。
- 最適パラメータがもたらす、過去のデータに対する予測結果
- オンライン学習アルゴリズムがパラメータを都度調整して得た予測結果
基本的に、1.は2.よりも良いものとなります。2.の結果が1.の結果に対してどの程度「悪くないか」数値化したものを後悔と呼び、それを最小化しようとする枠組みを後悔最小化と呼びます。
ここで、「最適パラメータ」はもちろん、実際にデータが到着するまでわからないということに注意が必要です。(このことから、最適パラメータを「後知恵」(hindsight)と呼ぶ文献もあります。)
オンライン学習の応用分野
アカデミックを中心に、様々な実験がなされているようです。
ユーザー投稿(User-Generated Content)のスパム判定
Yahoo!のような膨大な数の投稿をユーザーから受信するサイトにおいて、最新情報を基にスパム判定するための枠組みが研究されています。「静的なスパム判定ロジックは攻撃者に容易に潜り抜けられてしまう」ことから、機械学習によるスパム判定は今後不可欠になると言われています。 このような用途において、オンライン学習は以下の特徴を持っています。
- 過去の投稿を手元に置くことなく、最新投稿のみから学習することが出来る
- 日々変化するスパムのパターンには、「一括学習・適用」というバッチ学習の枠組みでは対応できない。最新情報を基に学習し続けるオンライン学習であれば対応出来る
下記のオンライン学習手法の研究論文では、従来の機械学習手法と同様に、担当者が「スパム/非スパム」でラベリングしたデータを用いて訓練を行っています。
スポンサードリンク表示内容決定のための、より高精度なCTR(クリック率)推定
Googleのスポンサードリンクは、検索クエリ(検索キーワード)に基づいて複数の広告を表示します。表示される広告を決定するシステムは、広告の掲載順位とスポンサーへの課金額も同時に決定しています。 これらを決定する基準として用いられるのが、広告のCTR(Click-Through-Rate、クリック率)です。よって、システム内でCTRを求める必要がありますが、キーワードの数が膨大であることから、ほとんどの広告にはキーワードに紐付いた出力実績・クリック実績がありません。このことから、実績のない広告に対する高精度の推定が必要とされています。
実は、Googleにおけるスポンサードリンクの精緻化というテーマにおいて、オンライン学習アルゴリズムが実験で良いパフォーマンスを上げているというのです。
新規手法として提案されたオンライン学習に基づくCTR予測システムは、新しいクリック(もしくは新しい未クリック)を基に、1日あたり何十億回も予測内容の更新を行います。そのようなシステムは最新の趨勢の下でCTR予測が出来る訳ですから、予測精度が上がるであろうことは素人にも想像できますね。
なお下記の参考文献において、予測の手法自体は、ロジスティック回帰というよく知られた方法が用いられています。
既存ライブラリについて
オンライン学習がアカデミックにおいて注目されるにつれ、既存の機械学習ライブラリにもオンライン学習のための機能が追加され始めているようです。
また、オンライン学習を目的としたライブラリの開発もなされていますので、これらをまとめていきます。
Vowpal Wabbit
大規模データ解析のための効率的なアルゴリズムを提供しているライブラリで、オンライン学習がその中核をなしています。
C++ライブラリのBOOSTを用いています。
LIBOL - A Library for Online Learning Algorithms
オンライン学習を目的として開発されたライブラリで、二値分類や多値分類が代表的なユースケースです。
内蔵されているアルゴリズムについてマニュアルに記載があり、情報がよく整理されています。
MATLAB/Octaveインタフェースです。
Hivemall
Hadoop上で動作する機械学習ライブラリです。既にオンライン学習用の機能が追加されており、RDB上のトランザクションデータからオンライン学習し、予測が行えます。
Jubatus
オンライン学習を目的として開発されたライブラリで、SparkやPython/scikit-learnとの連携動作が可能です。
オンライン学習が機械学習のスタンダードになる日も近い?
オンライン学習は、単一のストレージにはとても保管しきれないようなビッグデータに対し、その全体を保管せず逐次的に処理するというアプローチを可能にしてくれます。
このことからオンライン学習は、Hadoopのような分散処理技術による(バッチ)機械学習と対置されることもあります。
これは、両者に排他性があるという意味ではありません(むしろオンライン学習は並列計算と相性がいいと言われています)。
従前は分散処理技術を援用しなくては分析が不可能だった巨大なデータに対し、オンライン学習ライブラリを使えば単一マシン上での処理もできるという示唆なのです。
つまり、エンジニアからみれば、ビッグデータに対する解析方法の選択肢が新たに生まれつつあるということになります。
システムの全体要件に合わせて柔軟に実装方法を変えられるということですから、有難い話であるように思います。
将来的にはオンライン学習の枠組みが汎用化し、リアルタイム性の高い事象や、膨大なデータの解析が手軽に出来る時代が来るのかもしれません。 そのような時代の到来は、今よりも多くの技術者に、機械学習に取り組むチャンスをもたらすかもしれませんね。
参考文献
関連記事
- 2017/12/28 機械学習・統計学・最適化の違いについてまとめてみた 「機械学習」という手法は、システム開発の現場で用いられる事例が急増しています。一方、「統計学」という分野も機械学習と同様にデータを扱い、やはり多数の事例があります。本記事は「機械学習と統計学の違い」について整理することを試みます。
- 2017/06/30 Chainerを使ってMarkov chain(マルコフ連鎖)を書いてみる 本記事は、Python上で動作するニューラルネットワークのライブラリ「Chainer」を使ってマルコフ連鎖を実装、様々な実験を行うものです。本来関係のない両者を結びつけることでどんなメリットが得られるのでしょうか?
- 2017/01/06 オンライン広告をどのようにプロモーションする? - 劣モジュラ性と局所探索で解決 前回の記事でソーシャルマーケティングの例であるオンライン広告問題の定義と劣モジュラ性の関連について説明しました。今回はオンライン広告問題において、どのようにインフルエンサーを見つけ、プロモーションを行っていくのかを紹介したいと思います。
- 2016/12/28 ソーシャルマーケティングシステムを単純なアルゴリズムで実装する - 劣モジュラ最適化と貪欲法 ソーシャルメディアを用いたバイラルマーケティングの例は多数あります。実は、このバイラルマーケティングの裏には、劣モジュラ性という数学的性質に基づいて設計されたシステムが使われています。
- 2016/11/28 機械学習モデルの汎化を妨げる過学習とは? - 旗揚げ画像の二値分類を例に この記事では機械学習に関連する以下のトピックについて解説し、機械学習を学んだことのない方が、汎化と過学習に関する観念的な理解を深めることを目指します。