Trie(トライ木)を用いた検索は高速・省メモリ
Trie(= Retrieval tree, 検索木)はテキスト処理において必需品と言えるデータ構造です。辞書検索、日本語入力、サジェストの実装や、形態素解析に使われる辞書(形態素辞書)が主な用途と言えるでしょうか。Pythonの自然言語処理パッケージNLTK(Natural Language Tool Kit)でも、形態素解析にトライ木を用いています。
参考:http://www.nltk.org/book-jp/ch12.html
Trie(トライ木)とは?
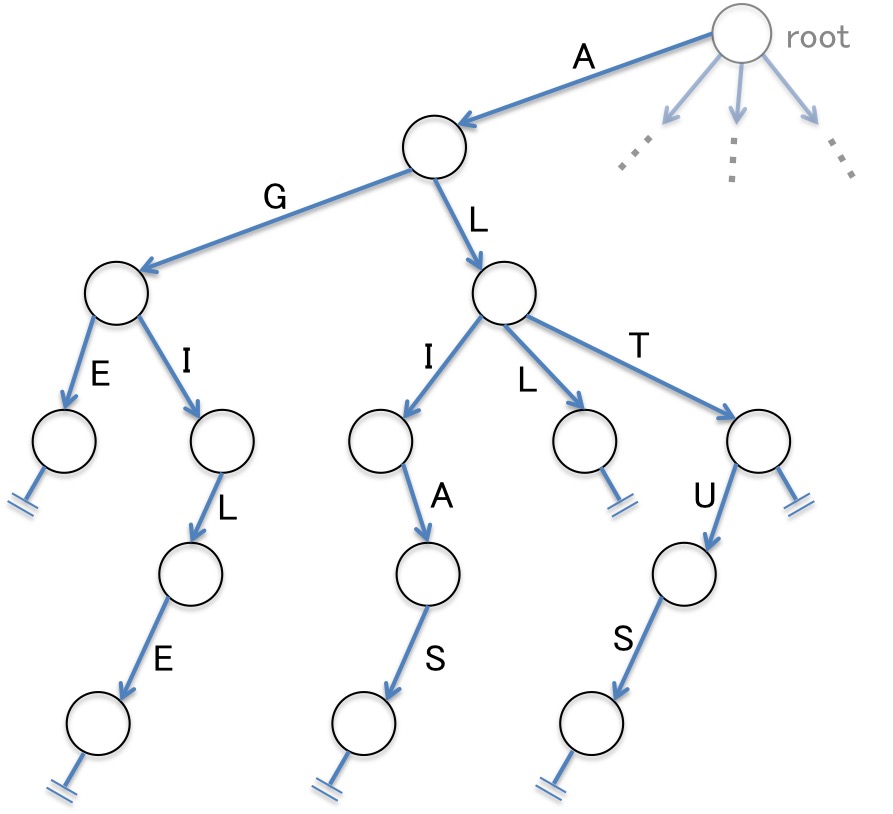
例として、辞書として使われているトライ木の「A」から始まる単語を格納した部分を図示してみました。このように、探索木の各エッジに文字を割り当て、根ノードから葉ノードに至る経路(path)上の文字を拾っていった時の文字列によって辞書を表現します。この辞書には、「AGE」「AGILE」「ALIAS」「ALL」「ALT」「ALTUS」という6つの単語が含まれています。このように、経路によって定義される個々の単語をキーと呼びます。 形態素解析におけるトライ木の活用で言えば、各ノードには形態素が対応し、葉ノードまでの経路が文章を表すことになります。
なぜ辞書検索や形態素解析にトライ木が使われるかというと、大きく下記の理由によります。
- 共通接頭辞検索(Common-Prefix Search)に適したデータ構造であること
- 膨大な辞書データを格納する場合や、文字の種類が多い場合でも、検索が高速であること
- 木構造を表現する際にLOUDSなどの簡潔データ構造を用いれば、省メモリで辞書を表現出来ること
LOUDSとは?
LOUDSとは、木構造をメモリ効率よく表現するための簡潔データ構造です。 Trieに使う場合のLOUDSの概念図を下図に示します。
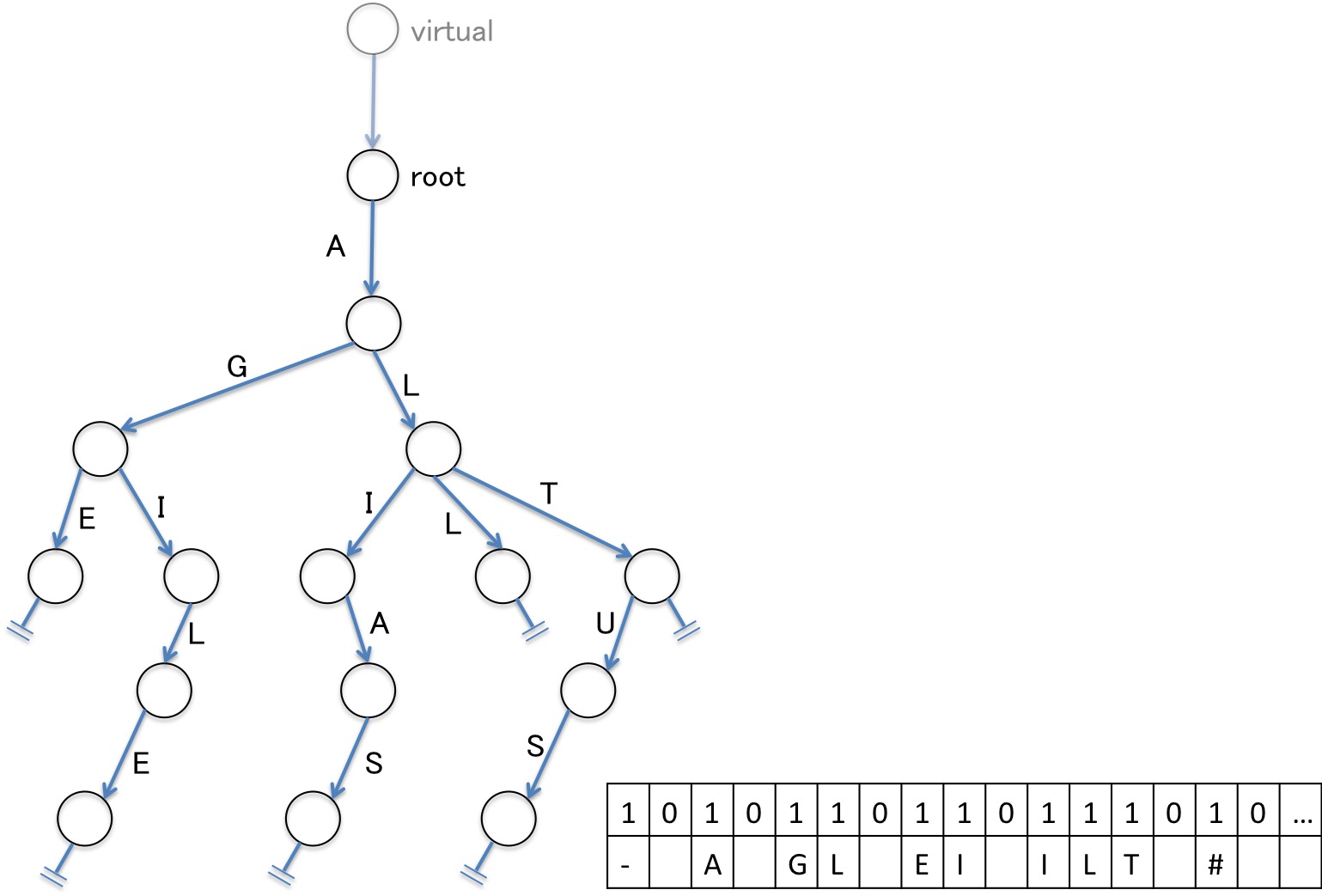
左側の木がLOUDSによって表現されるTrieであり、右側の表がLOUDS(ビット列)及び、その付加情報としての文字です。 LOUDSとは、仮想ノード(Virtual node)を根ノードの親として用意したあと、下記の手続きで構築されるビット列を用いて、木構造を表現しようというデータ構造です。
- ノードが持つ子ノードの数に等しい数だけ「1」のビットを立て、そのあとに「0」のビットを立てる
- 仮想ノードから幅優先で木を探索し、1.の手続きを繰り返す
LOUDSは、木構造を最小に近いビット数で表現できます。また、Trieとして用いる際にも、接頭辞検索などの要求に対する処理をある程度高速に行える、バランスの良いデータ構造(簡潔データ構造)であることが知られています。
有名なところでは、Google日本語入力のオープンソース版であるMozcでは、LOUDSを用いてTrieを表現しています。 一方、工藤 拓氏(現Google)が開発した著名なオープンソース形態素解析エンジンMeCabには、ダブル配列(Double-Array)という別のデータ構造に基づくTrieが使われています。
弊社の実績 - 全文検索やSNS解析にトライ木を応用
弊社でも、トライ木(またはトライ木に類するデータ構造)が随所で活躍しています。 例えば、ある「案件情報検索サイト」の全文検索にサジェスト機能を付けた際、サジェストの表示(フロントエンドUI)はAutocompleteを用いましたが、データの辞書化と辞書検索は下記の要領で自作しました。
- 案件情報テキストから単語を抽出
- 辞書をトライ木で表現
- 共通接頭語検索によりサジェストを出力(出現頻度順に10個)
他には、「ある特定の語順が出現したツイートを抽出する」SNS解析システムの実装にトライ木を応用しました。 そのシステムの概略と、具体的な実装上の課題については、今後の記事で紹介していきたいと思います。