Trieを実装する上で必要不可欠な、データ構造の工夫
前回のブログで、辞書検索、サジェスト、形態素解析などを実装するのに使われるTrieの概略を紹介しました。
木構造の各エッジに文字のラベルを付けることで辞書を表現するという抽象的な説明を与え、それを実現するLOUDSという簡潔データ構造を紹介しました。 今回はLOUDSとは別の、Double Array(ダブル配列)というデータ構造で実際にTrieをPythonで構築し、共通接頭辞検索を行えるようにします。 実装方法については 『日本語入力を支える技術』(徳永, 2012)、通称「徳永本」に準拠しますので、同著を読まれた方が実装を試みる際の参考にもなると思います。 また、Double arrayのエッセンスを紹介していきますので、参考書籍をお持ちでない方もDouble arrayによるTrieの実装について理解できることを目指しています。
前提:Trieを実装する上で、データ構造の選択は重要
まず、Trieを実装する際のデータ構造として、LOUDSやDouble Arrayといった様々な選択肢が存在する背景を紹介しておきます。 検索の高速性を担保しつつTrieを実装する素朴な方法として、各ノードからの文字ごとの遷移先をテーブルに格納しておくというやり方が挙げられます。
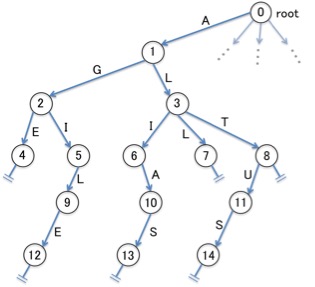
このようなTrieを想定してみましょう(ノードの番号は幅優先で付与)。
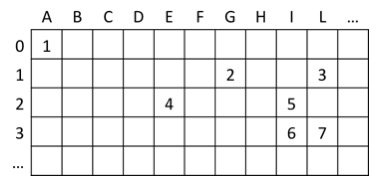
上記のTrieに対応するテーブルが上図です。各セルを (行ラベル, 列ラベル)という組で表すことにすると、例えば (2, E)に4が格納されていることになりますね。
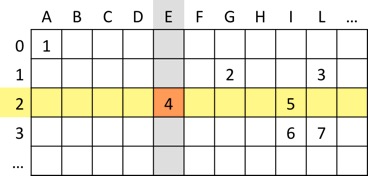
これは、Trie上の「2」というラベルが付いたノードから、文字「E」のラベルがついたエッジを辿ることで、「4」 というラベルが付いたノードに遷移できることを表します。 このようなテーブルを二次元配列などの形式でメモリ上に保持すれば、例えば「AGI」という入力に対してTrie上のノード5に効率よく遷移出来ます。そのことを、Pythonのコードを用いて確かめてみましょう。
【Python】テーブルによるTrieと共通接頭辞検索ソースコード
ここからは、GitHubで公開した下記のソースコードを引用しながら解説を進めます。100行に満たないソースコードですが、『日本語入力を支える技術』で解説されている「テーブルによるTrieの実装」をそのまま実現しています。
https://github.com/msato-ok/trie-master/blob/master/tabletrie.py
まず辞書の生成ですが、’MyTrie’というクラスでTrieを表すものとし、’MyTrie’のオブジェクトが一つの辞書を表します。オブジェクトを生成する際には、語彙が格納された配列を入力します。
例えば下記のようにすると、辞書を生成することが出来ます。
テーブルによるTrieの構築について、アイデアは既にご紹介しましたので、その具体的な実装内容はソースコードをご覧ください(’MyTrie’クラスの’init’関数の中身)。
この時、共通接頭辞検索のコードは下記のようになります。
共通接頭辞検索のアルゴリズムは、入力として‘query’という文字列を取ります。例えば下記のようなものが考えられるでしょう。
出力は’query’が表すノード下にある全ての単語です。一例として、下記が正しい出力です。

上述したリンク先のリポジトリをcloneし、「tabletrie.py」を実行して頂くと、同様の結果が確認可能です。
テーブルによる実装の弱点と、Double arrayの必要性
この実装はシンプルな上、高速な検索が可能ですが、「Trieのノード数、および使われる文字数、それぞれに比例したメモリが必要」という弱点があります。
つまり、この素朴な方法では、文字数が大きくなったり、辞書の単語数が大きくなると、メモリに乗り切らないという問題が生じてしまうのです。 そこで、「よりメモリ効率の良いデータ構造を用いれば、巨大な入力(語彙)に対しても使えるようなTrieによる辞書が実装できないか」という問が生じます。
Trieを格納・運用できるデータ構造については、検索の高速性をある程度犠牲にしてメモリ効率を上げていくというのが基本方針です。そのような「メモリ効率と高速性、両者のバランスが取れたデータ構造」を「簡潔データ構造」と呼びます。今回のテーマであるDouble array(ダブル配列)は、簡潔データ構造の一種です。
補足:Trieによる形態素解析と「文字数」の上限について
※この段落は読まなくても、理解上差し支えありません。
先ほど、テーブルによる実装は「Trieのノード数、および使われる文字数、それぞれに比例したメモリが必要」と述べました。 ここで「ノード数」は単語数に従って増大するため問題だということが伝わりやすいと思いますが、「文字数が大きくなる」というイメージは持ちづらいかもしれません。 アルファベットなら26文字、ひらがななら五十音といった風に、上限があるように感じられるので、問題がないと思われるかもしれません。 しかし形態素解析のような用途にTrieを用いたい場合は、文字数は増大の可能性があります。 形態素解析においては、「わがはいはねこである」という入力文章に対し、単語の結びつきの強さによって「吾輩は猫である」という文章と「我が杯羽根子である」という文章のどちらがもっともらしいかという判断を行います。このとき、先ほどの「文字」にあたるものは「単語」(ex. 吾輩、杯、羽根、etc.)であり、その数はアプリケーションの用途によります。 よって文字数の上限を定めることはできず、テーブルによるTrieの「文字数に比例してメモリが必要」という性質は大きな障壁となるのです。
Double arrayによるTrieの実装
Double arrayによるTrieの実装をPythonで行ったコードは、下記URLからアクセスできます(GitHubリポジトリ)。
https://github.com/msato-ok/trie-master/blob/master/double_array_trie.py
まずは、テーブルによる素朴な実装とDouble arrayによる実装はどう違うのか、簡単に対比してみたいと思います。
テーブルによる実装では、Trieのノードそれぞれについて、各文字による遷移先を示すための行(すなわち配列)を用意しました。
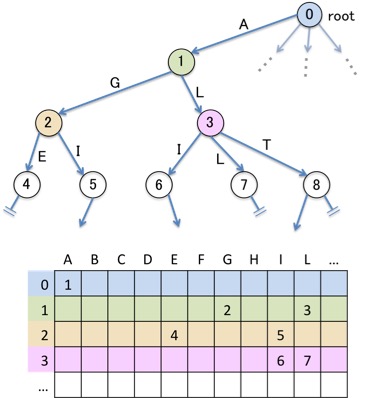
一方、Double arrayを用いることは、語彙(入力する単語の集合)がどんなに大きくても、2本の配列だけでTrie全体を表現することを可能にしてくれます。 「ダブル配列」という言葉からは配列の本数が倍加するような印象を受ける方もおられるかもしれません。そうではなく、「どんなに巨大な辞書でも、2本の配列だけで、対応するTrieを表現できる」ことが、このデータ構造の特色なのです。
例えば、下記が上述のTrieに対応する、Double arrayの例です。
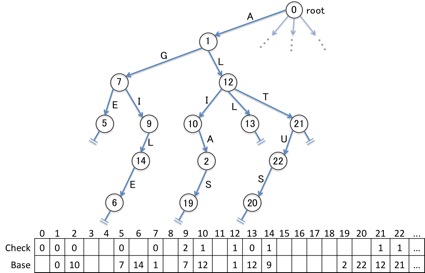
ここでDouble arrayとは、上図にあるCheck, Baseという2つの配列のことです。2本の配列に格納された値を適切に読み込んでいくことで、上記のTrieを再現したり、共通接頭辞検索を高速に行えるようになっています。 しかし、なぜこの2本の配列によってTrieを表現出来るのか、配列そのものを見ていても理解は難しいでしょう。ですので一旦 Check, Baseが何を表すのかということは忘れることにします。
代わりに、上図のもう一つの特徴的な点に着目します。それは、Trieのノードに付与された番号が先ほどとは変わっているという点です。 これはデタラメな数値ではなく、Double arrayによるTrieの構築アルゴリズムに従って論理的に付けられた番号です。その規則を知ることで、Double arrayによるTrieの構築と、検索に用いる際のアルゴリズムが直観的に理解しやすくなります。
Double arrayにおける各ノードの番号付け規則
番号付け規則を理解するための「データ構造もどき」
少し遠回りですが、Double arrayについて理解するためのステップとして、Double arrayから幾つかの要素を省いた「データ構造もどき」について考えてみると、理解しやすくなります。 すなわち、下記のシンプルな規則に基づいてTrie(?)を構築するとどうなるか、想像してみましょう。
- 各ノードの番号として、ノードに入ってくるエッジのラベル「A, B, C, …」を、「1, 2, 3, …」に置き換えた数値を採用する
結果は下図のようになります。
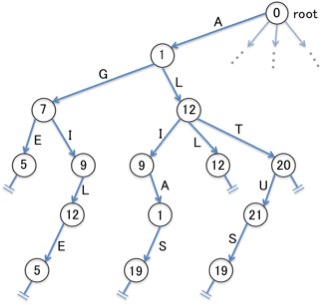
ここでは便宜的にノードとノードの間にエッジを引いて、Trieの形を保たせていますが、実際に情報として存在するのは各ノードの番号だけです。 この「図」をTrieだと考えて運用しようとすると、2つの障害が発生することを、下図で示してみました。
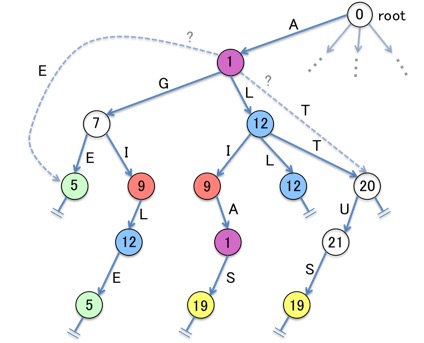
- 複数のノードに同じ番号が付けられてしまい、例えば「1」のノードから「L (12)」で遷移しようとしたとき、複数ある「12」のノードのうちどれに遷移すればいいかわからない
- 「1」のノードから「E (5)」で遷移しようとしたとき、遷移先は存在しない(「1」の子ノードに「5」のラベルが付いたノードはない)にもかかわらず、離れた「5」のノードに遷移できるように見えてしまう
Double arrayは、この2つの症状を克服するために工夫を加えたものと解釈することが出来ます。
正しいノード遷移を可能にするための2つの工夫
まず前述した問題1.については、ノードの番号が重複しないようにすれば解決します。 ノード間の番号の重複を解決するために、ちょっとした工夫を加えたものが下図です。
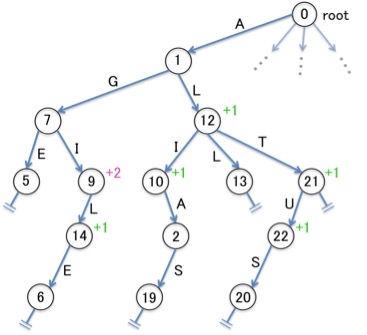
こちらは、一部のノードに「+1」もしくは「+2」という数値を持たせ(もっと大きな値を持たせてもよい)、ノードの番号を付ける際の規則を、下記のようにほんの少しだけアップデートした結果の図です。
- 各ノードの番号として、親ノードの持つ数値に対し、ノードに入ってくるエッジのラベル「A, B, C, …」を、「1, 2, 3, …」に置き換えた数値を加えたものを採用する
ひとまずこのようにすると、ノードの番号の重複については解決出来ることになります。
上図では、「子ノードの番号に加えた量」を、親ノードの傍に付記していました。実際にメモリ上でその値を記憶しておくためには配列をよく用いますので、親ノードの番号を添え字として、配列の中に値を格納してみることにしましょう。
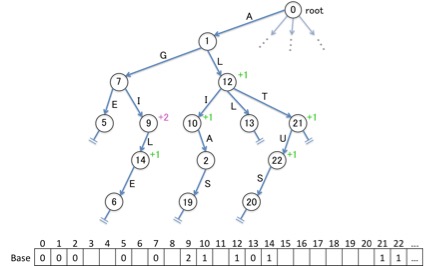
実はこの配列が、冒頭で天下り的に示した「Double array」の「Base」という配列に一致するものとなっています。 要は、Baseというのは、「子ノードの番号を付ける際のベースとなる量」を表す数値であり、ノードの番号を重複させないために加えるものなのですね。
もう一つの工夫は、問題2.を解決するためのものです。 Base配列を導入することでノードの番号の重複は解消されましたが、「遷移出来ないノードに遷移出来るように見える」という問題は依然として残っています。例えば:
- ノード「0」から「E (5)」という文字によって、ノード「5」に遷移出来るように見える
- ノード「12」から「F (6)」という文字によって、ノード「7」に遷移出来るように見える(ノード『12』は+1というBaseの値を持つことに注意)
これを解決する方法は実は単純です。各ノードに対し、親ノードの番号を覚えさせておくことで、子ノードへ遷移しようとするとき「遷移先が自分の子ノードかどうか」チェック出来るようにすれば良いのです。
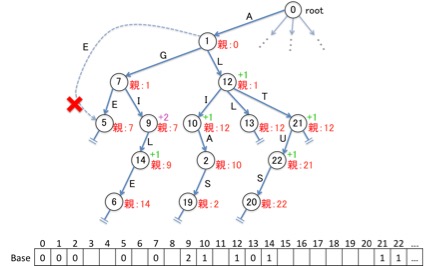
このようにすると、子ノードではないノードへと遷移してしまう問題を防ぐことが可能になります。 例えば「1」というノードからは「E (5)」という文字によってノード「5」に遷移出来るように一見見えますが、ノード「5」の親は「7」です。つまりノード「5」はノード「1」の子ではありませんから、遷移は出来ないということがわかるのです。
実はこの「各ノードの親を記憶させた配列」が、Double arrayのもう一つのデータである「Check」という配列にあたるのです。

上図は最初に天下り的に示した「Double arrayによるTrie」と同じ図になっています。 Double arrayに格納されているデータが何を表すかに関する、概念的な説明は以上です。
【Python】Double arrayを構築し、共通接頭辞検索を行うコード
https://github.com/msato-ok/trie-master/blob/master/double_array_trie.py
上記ソースコードでは、与えられた語彙(単語の集合)に対し、実際にDouble arrayに基づくTrieを構築し、共通接頭辞検索を行うことが出来ます。 行数は130行程度と、tableによる実装とさほど変わりません(ただし、高速化のための工夫は行っていないことにご注意ください)。
Check, Baseへの値の入力は、MyTrieクラスのコンストラクタ内で行っています。ここでは入力語彙に基づき、Check, Baseに適切な値を格納していきます。
また、double_array_trie.pyのMyTrie. common_prefix_search関数は、Check, Base二つの配列を用いて下記のような処理を行うことが出来ます。
- 入力語彙のうち、「AL」から始まるすべての単語を出力する(共通接頭辞検索)
- 入力語彙のうち、「ALP」や「ALA」から始まる単語が存在しないことを判定する
Trieをシステム開発に応用する
弊社はフルスクラッチの開発案件を得意としており、Trieやそれに類するデータ構造を用いて、共通接頭辞検索を応用した機能を柔軟に実装することが出来ます。 例えば、「求人案件情報の検索において、全文検索に基づくサジェストを出したい」と言った要求は、「Java」という入力に対して「Java」や「Java エンジニア」、「JavaScript」といった出力を返すことなので、共通接頭辞検索を行うことに他なりません。 「できない」と思えるような技術課題について、技術力を駆使してお応えする準備がございます。まずはお気軽に、開発案件のご相談を頂ければ幸いです。
また、様々なデータ構造を活用して、顧客の課題を解決する最善の方法を模索したいエンジニアからの求人応募も常にお待ちしております。ぜひ「採用情報」をご覧になってみてください。
関連記事
- 2017/09/06 テキスト処理に使われるTrie(トライ木)とLOUDSに関する概略 Trieはテキスト処理において必需品と言えるデータ構造です。辞書検索、日本語入力、サジェストの実装や、形態素辞書が主な用途と言えるでしょうか。Pythonの自然言語処理パッケージNLTKでも、形態素解析にトライ木を用いています。
- 2022/11/21 Python の linter python 用のプロジェクトで使っている linter など
- 2020/06/15 PySparkの分散される処理単位であるクロージャと共有変数の仕組み Spark では、処理が分散されて、複数のノードやスレッドで実行されますが、分散される処理の塊を、どう配信しているのか?加えて、複数のタスク間でのデータの共有とか、集約するための仕組みがどうなっているのか?少しだけ説明します。
- 2018/07/18 全文検索を自社サイト・社内サーバーに構築したいクライアントのための留意点 システム開発における「全文検索」の実装方式・コスト・性能に関して、クライアント企業の方にも腹落ち頂けるようまとめました。grep型と索引型の違いに関する平易な解説を記載しているので、これらをクライアントに解説されたい開発者にもオススメです。
- 2018/06/14 zip, compress, gzip, bzip2 - ファイル圧縮の形式に関する覚書 ファイルサイズや検索性に大きく影響する「圧縮形式」。本記事ではメジャーな圧縮形式について紹介していくと共に、『高速文字列解析の世界』(岡野原、2012)の内容と連動。エンジニアが処理内容を学習しやすいようまとめています。